writing
Draft #2: Bare-bones XML
In this article I break down how the XML syntax can be reduced to a minimal essence. In a few steps we will end up with a much simpler syntax which is still human-readable and at the same time much more efficient for machines to process. It is trivially mappable to XML and DOM, so existing knowledge and tools can be leveraged when working with it. To do that would be to take a step towards realizing a mad vision of total intercommunication of all software systems.
Closing tags
The first most obvious candidate to eliminate in order to make XML more minimal are the closing tags. They increase the volume of XML significantly while complicating editing and processing. It is surely possible to get used to reading them and an argument can be made for them as an useful redundancy device. But our goal here is getting to the essence, and they are certainly not it.
Let’s look at an example (source):
<?xml version="1.0" encoding="UTF-8"?>
<book xml:id="simple_book" xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>Very simple book</title>
<chapter xml:id="chapter_1">
<title>Chapter 1</title>
<para>Hello world!</para>
<para>I hope that your day is proceeding <emphasis>splendidly</emphasis>!</para>
</chapter>
<chapter xml:id="chapter_2">
<title>Chapter 2</title>
<para>Hello again, world!</para>
</chapter>
</book>
To get rid of the closing tags we can rewrite it like this:
<?xml version="1.0" encoding="UTF-8">
<book xml:id="simple_book" xmlns="http://docbook.org/ns/docbook" version="5.0"/
<title/Very simple book>
<chapter xml:id="chapter_1"/
<title/Chapter 1>
<para/Hello world!>
<para/I hope that your day is proceeding <emphasis/splendidly>!>
>
<chapter xml:id="chapter_2"/
<title/Chapter 2>
<para/Hello again, world!>
>
>
i.e. we replace the > in opening tags with / and we delete all characters except the final > from closing tags.
This is no longer valid XML, but it looks quite similar and it has identical logical structure. The original XML can be recreated from it exactly.
With this transformation we went from 458 to 384 characters, losslessly reducing the size of the data by over 16%.
Quote marks and equals signs
The XML syntax has 5 special characters which may require escaping[1][2]: <, >, &, ', ".
We can reduce that by 40%, by getting rid of the apostrophe and the quote mark. How do we do that? We simplify the attribute syntax, like so:
- We replace all
=followed by opening"with<. - We replace all closing
"with>.
Once we do that, our data looks like this:
<?xml version<1.0> encoding<UTF-8>>
<book xml:id<simple_book> xmlns<http://docbook.org/ns/docbook> version<5.0>/
<title/Very simple book>
<chapter xml:id<chapter_1>/
<title/Chapter 1>
<para/Hello world!>
<para/I hope that your day is proceeding <emphasis/splendidly>!>
>
<chapter xml:id<chapter_2>/
<title/Chapter 2>
<para/Hello again, world!>
>
>
We didn’t have very many attributes here, so the gain is not substantial for our sample (we are now at almost 18% reduction). However for XML with a lot of attributes and/or escapes the gain will grow significantly. Particularly, every ' and " will turn into ' and " – that’s 5 characters saved for each occurence. Plus readability and convenience are significantly improved.
Entities
Continuing the previous point in the spirit of being minimal, we will dispense with almost all entities altogether. Our format shall only support three fixed pseudoentities:
&&
&<
&>
which resolve to:
&
<
>
respectively.
With this move, we leave representing all special characters up to underlying encoding. The user is also always free to overlay their own entity mechanism on top of our simple format, if they wish. This makes for a better separation of concerns.
In today’s world, where UTF-8 is widely supported, entities are not a common sight anyway.
Removing entities not only makes our format leaner and simpler, but also more secure[1][2].
Our example uses no entities, so we save nothing on this. In general though replacing each unnecessary entity with a single character provides a very substantial reduction. Looking at this list an average ratio of 5:1 would be an underestimate.
Under compatible encodings we still preserve the ability to translate between XML and our format without loss of relevant information. Translating XML entities is a one-way operation, but that’s fine for our purposes. Under incompatible encodings we’d of course still be able translate all offending characters to XML entities.
Going ergonomic
To avoid confusion with XML proper and cut the number of keypresses needed to enter all special characters in half, as a final touch, we will perform a simple character substitution:
- Replace all
<with[ - Replace all
>with] - Replace all
&with`
This turns our sample into:
[?xml version[1.0] encoding[UTF-8]]
[book xml:id[simple_book] xmlns[http://docbook.org/ns/docbook] version[5.0]/
[title/Very simple book]
[chapter xml:id[chapter_1]/
[title/Chapter 1]
[para/Hello world!]
[para/I hope that your day is proceeding [emphasis/splendidly]!]
]
[chapter xml:id[chapter_2]/
[title/Chapter 2]
[para/Hello again, world!]
]
]
Which is compatible with the canonical Jevko syntax.
Going pretty
Now, let’s add some colors:
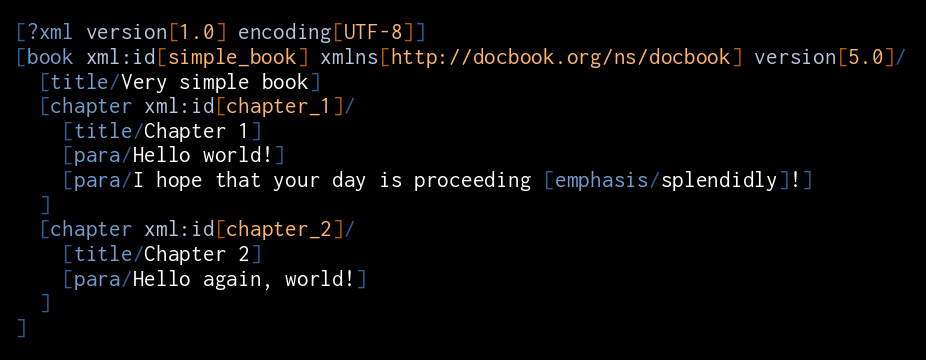
and compare again:
<?xml version="1.0" encoding="UTF-8"?>
<book xml:id="simple_book" xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>Very simple book</title>
<chapter xml:id="chapter_1">
<title>Chapter 1</title>
<para>Hello world!</para>
<para>I hope that your day is proceeding <emphasis>splendidly</emphasis>!</para>
</chapter>
<chapter xml:id="chapter_2">
<title>Chapter 2</title>
<para>Hello again, world!</para>
</chapter>
</book>
Not too bad if you ask me.
Conclusion
(TODO)
See also
© 2022 Darius J Chuck