writing
Horse and carriage
This data from Wikipedia:
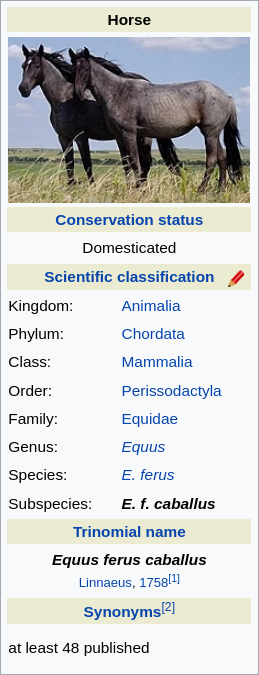
Could be represented in Jevko as follows:
Name [Horse]
Conservation status [Domesticated]
Scientific classification [
Kingdom [Animalia]
Phylum [Chordata]
Class [Mammalia]
Order [Perissodactyla]
Family [Equidae]
Genus [Equus]
Species [E. ferus]
Subspecies [E. f. caballus]
]
Trinomial name [
[Equus ferus caballus]
[Linnaeus, 1758]
]
Synonyms [at least 48 published]
If we parse that using the high-level grammar, we will get a parse tree like:
{
"subjevkos": [
{
"prefix": "Name ",
"jevko": {
"subjevkos": [],
"suffix": "Horse"
}
},
{
"prefix": "\n\nConservation status ",
"jevko": {
"subjevkos": [],
"suffix": "Domesticated"
}
},
{
"prefix": "\nScientific classification ",
"jevko": {
"subjevkos": [
{
"prefix": "\n Kingdom ",
"jevko": {
"subjevkos": [],
"suffix": "Animalia"
}
},
{
"prefix": "\n Phylum ",
"jevko": {
"subjevkos": [],
"suffix": "Chordata"
}
},
{
"prefix": "\n Class ",
"jevko": {
"subjevkos": [],
"suffix": "Mammalia"
}
},
{
"prefix": "\n Order ",
"jevko": {
"subjevkos": [],
"suffix": "Perissodactyla"
}
},
{
"prefix": "\n Family ",
"jevko": {
"subjevkos": [],
"suffix": "Equidae"
}
},
{
"prefix": "\n Genus ",
"jevko": {
"subjevkos": [],
"suffix": "Equus"
}
},
{
"prefix": "\n Species ",
"jevko": {
"subjevkos": [],
"suffix": "E. ferus"
}
},
{
"prefix": "\n Subspecies ",
"jevko": {
"subjevkos": [],
"suffix": "E. f. caballus"
}
}
],
"suffix": "\n"
}
},
{
"prefix": "\nTrinomial name ",
"jevko": {
"subjevkos": [
{
"prefix": "\n ",
"jevko": {
"subjevkos": [],
"suffix": "Equus ferus caballus"
}
},
{
"prefix": "\n ",
"jevko": {
"subjevkos": [],
"suffix": "Linnaeus, 1758"
}
}
],
"suffix": "\n"
}
},
{
"prefix": " \nSynonyms ",
"jevko": {
"subjevkos": [],
"suffix": "at least 48 published"
}
}
],
"suffix": ""
}
Elements of the parse tree
There are only 4 distinct keys in this parse tree: jevko, subjevkos, prefix, and suffix.
These identify all the elements of the parse tree.
jevko is the basic element. Each jevko is made of two other elements: a list of subjevkos and a suffix.
The top-level object (the root) of the parse tree is therefore a jevko.
Each element of the subjevkos list is called a subjevko.
Like a jevko, a subjevko is also made up of two elements: a prefix and a nested jevko. Since it carries a nested jevko, a subjevko is responsible for the recursive nature of the tree. jevko is the tree and subjevko is the subtree.
Finally, both prefix and suffix are simple strings. They are the leaves of our parse tree.
Simple Jevkos
Let’s take the top subjevko:
{
"prefix": "Name ",
"jevko": {
"subjevkos": [],
"suffix": "Horse"
}
}
which corresponds to the fragment:
Name [Horse]
The jevko of this subjevko is:
{
"subjevkos": [],
"suffix": "Horse"
}
this simply corresponds to:
Horse
we will call a jevko like that simple: its list of subjevkos is empty, so it only carries a suffix. In other words it is a tree with no subtrees and a single leaf.
Syntactically, a simple jevko contains no brackets.
Complex Jevkos
Conversely, a complex jevko is one with a nonempty list of subjevkos.
For example the following fragment:
Fragment #1: complex Jevko
[Equus ferus caballus]
[Linnaeus, 1758]
and its corresponding parse tree:
Parse tree #1: complex Jevko
{
"subjevkos": [
{
"prefix": "\n ",
"jevko": {
"subjevkos": [],
"suffix": "Equus ferus caballus"
}
},
{
"prefix": "\n ",
"jevko": {
"subjevkos": [],
"suffix": "Linnaeus, 1758"
}
}
],
"suffix": "\n"
}
is a complex jevko. It has 2 subjevkos. Each of these contain a simple jevko.
Syntactically a complex jevko contains brackets.
Jevko as a sequence of characters, a string
A simple jevko can be interpreted as a string.
This could be done with the following JavaScript function:
const jevkoToString = (jevko) => {
return jevko.suffix
}
For example it would turn this:
{
"subjevkos": [],
"suffix": "Horse"
}
into this:
"Horse"
Jevko as a list of values
A complex jevko can be interpreted as a list.
For example parse tree #1 can be converted to a list of strings with the following JavaScript function:
const jevkoToListOfStrings = (jevko) => {
return jevko.subjevkos.map(({jevko}) => jevkoToString(jevko))
}
It will produce:
[
"Equus ferus caballus",
"Linnaeus, 1758"
]
Subjevko as a pair
Name [Horse]
has the following parse tree:
{
"subjevkos": [
{
"prefix": "Name ",
"jevko": {
"subjevkos": [],
"suffix": "Horse"
}
},
],
"suffix": ""
}
Each subjevko contains a prefix associated with a nested jevko. Syntactically, the prefix is all the text which comes before the opening bracket [, and jevko is everything after the bracket up to the matching closing bracket ].
Each subjevko looks and feels very similar to a key-value pair: the prefix can be interpreted as the key of the pair, and the nested jevko can be interpreted as the value of the pair.
Jevko as a collection of key-value pairs
A complex jevko can also be interpreted as a collection of key-value pairs.
For example:
Kingdom [Animalia]
Phylum [Chordata]
Class [Mammalia]
Order [Perissodactyla]
Family [Equidae]
Genus [Equus]
Species [E. ferus]
Subspecies [E. f. caballus]
const jevkoToMapOfStrings = (jevko) => {
return Object.fromEntries(
jevko.subjevkos.map(
({prefix, jevko}) => [prefix.trim(), jevkoToString(jevko)]
)
)
}
{
"Kingdom": "Animalia",
"Phylum": "Chordata",
"Class": "Mammalia",
"Order": "Perissodactyla",
"Family": "Equidae",
"Genus": "Equus",
"Species": "E. ferus",
"Subspecies": "E. f. caballus",
}
A list of subjevkos of a jevko can then be seen as a collection of key-value pairs. It is very straightforward to turn such a collection into a proper associative array or a map, such as a JavaScript Map, a plain JavaScript object, or an equivalent in any programming language.
const jevkoToValue = (jevko) => {
return Object.fromEntries(
jevko.subjevkos.map(
({prefix, jevko}) => [prefix.trim(), jevkoToValue(jevko)]
)
)
}
Putting it all together
const jevkoToValue = (jevko) => {
const {subjevkos} = jevko
if (subjevkos.length === 0) return jevko.suffix
const {prefix} = subjevkos[0]
if (prefix.trim() === '') return subjevkos.map(({jevko}) => jevkoToValue(jevko))
return Object.fromEntries(
subjevkos.map(({prefix, jevko}) => [prefix.trim(), jevkoToValue(jevko)])
)
}